For a data scientist, web scraping, or harvesting information from websites (when done legally) is often the only way to get data. There are excellent python libraries available for scraping, such as beautifulsoup, requests-html, selenium, and scrapy. The choice usually comes down to whether the website serves static or dynamic content, interaction with the server, light vs. heavy resource usage, scalability of the project and so on.
BeautifulSoup
BeautifulSoup is often a first choice for python developers, because coding is simpler and the application can run in the background at minimal load. The downside is that it works only with static websites that serve fixed content, and cannot be used with many modern websites that serve dynamic content generated by some scripts.
A good example of dynamic content is the landing page of Worldometer, which displays live world statistics on population, government and economics, society and media, environment, food, water, energy and health. Many of these numbers are updated several times a second, which are rendered by JavaScript.
Let’s see if BeautifulSoup can extract the “current world population” data from this page. Inspecting the page source in the browser’s developer tools shows that the two HTML elements responsible for this item are <span class="counter-number">...</span> for the counter and <span class="counter-item">...</span> for its name (see the image below).

In fact there are several "counter-number" and "counter-item" classes, one for each counter-name pair. I begin by creating a virtual environment in the project’s working directory and installing all necessary packages inside it:
> pipenv --python 3.10.9
> pipenv install requests, bs4, lxml, requests-htmlThe simple python code getWorldData.py below uses requests to download the page, and BeautifulSoup to parse it and extract the text strings (for counter and name) from the first pair of "counter-number" and "counter-item" classes.
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
class GetWorldData:
# constructor
def __init__(self, url) -> None:
self.url = url
# run code
def run(self) -> None:
response = requests.get(self.url, timeout=10) # get a response from the server
response.raise_for_status() # check status
soup = BeautifulSoup(response.text, "lxml") # parse page
count = soup.select(".counter-number")[0] # get first counter element
name = soup.select(".counter-item")[0] # get first name element
print(f"{name.text} --> {count.text}") # print text string of each element
def main() -> None:
url = "https://www.worldometers.info/"
worldData = GetWorldData(url) # create GetWorldData() object
worldData.run()
if __name__ == "__main__":
main()(A class declaration for such a short code is not usually necessary, defining a function getWorldData() instead of the method GetWorldData().run() would do just as well. Classes are helpful for large-scale OOP because of code re-usability and minimal redundancy. I use classes whenever possible regardless of code size, as long as they do not make the code harder to read.)
Executing the code gives the following output:
> pipenv run python getWorldData.py
Current World Population --> retrieving data...As expected, the code extracts the static name “Current World Population” but fails with the constantly updated population count, and gets the fixed message “retrieving data…” instead.
requests-html
The package requests-html (created by Kenneth Reitz, who is also the creator of requests) not only combines the features of both requests and Beautifulsoup, but is also capable of extracting dynamic content rendered by JavaScript. The code below downloads all world statistics from worldometers.info and saves those in a csv file.
#!/usr/bin/env python3
from requests_html import HTMLSession
class GetWorldData:
# constructor
def __init__(self, file, url) -> None:
self.file = file
self.url = url
# save data to file
def saveData(self, names, counts) -> None:
for name, count in zip(names, counts):
count_text = count.text.replace(",", "") # remove ","
name_text = name.text.replace(",", "")
self.file.write(f"{name_text}, {count_text}\n")
timeNow = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Stored world data at {timeNow}")
# run code
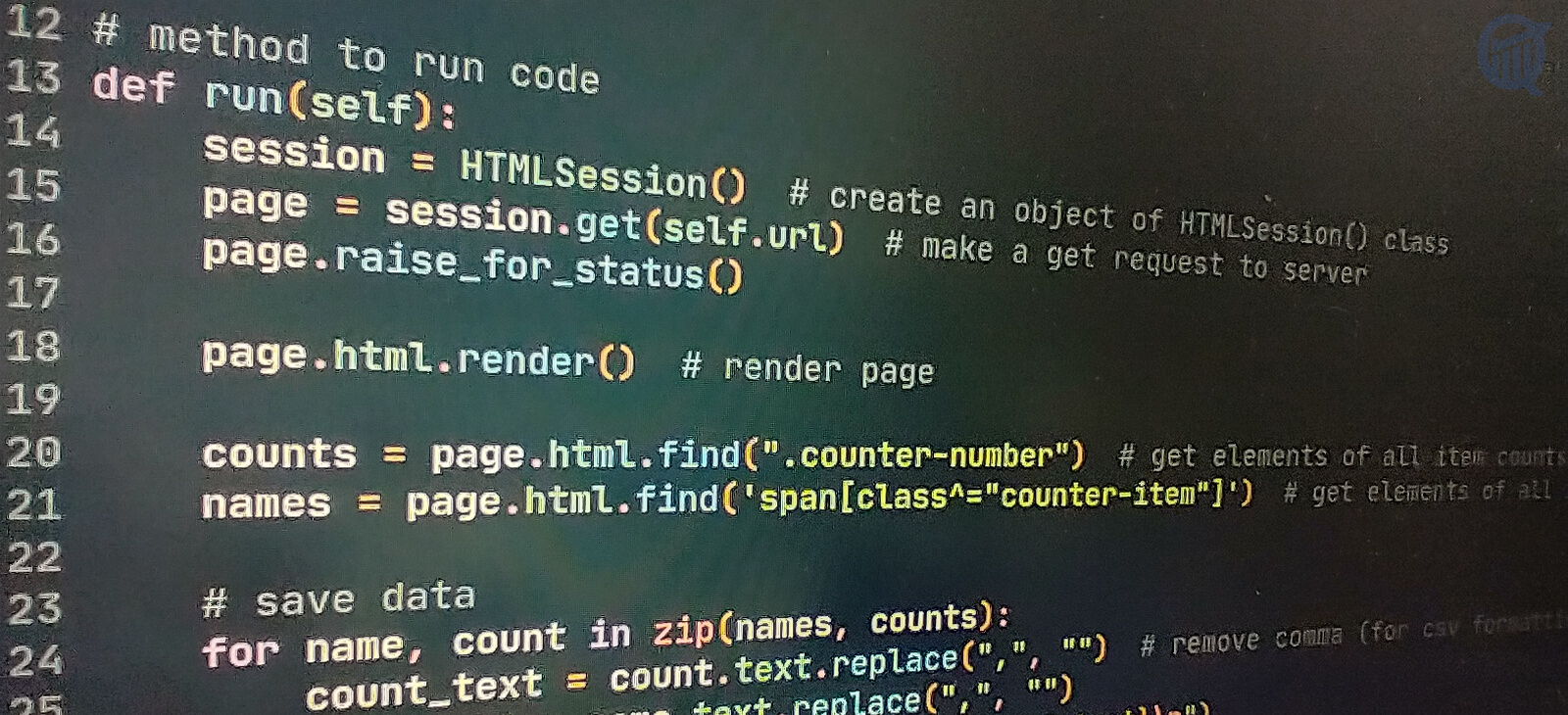
def run(self) -> None:
session = HTMLSession() # create an object of HTMLSession() class
page = session.get(self.url) # make a get request to server
page.raise_for_status()
page.html.render() # render page
counts = page.html.find(".counter-number") # get elements of all counts
names = page.html.find('span[class^="counter-item"]') # get elements of all names
self.saveData(names, counts) # call saveData() method
def main() -> None:
url = "https://www.worldometers.info/"
with open("../Results/world_data.csv", "a", encoding="utf8") as file:
worldData = GetWorldData(file, url) # create GetWorldData() object
worldData.run()
if __name__ == "__main__":
main()There are couple of differences from the BeautifulSoup code above. First, requests-html needs the HTMLSession() class to download the page source. Second, the page is rendered with response.html.render() for extracting the dynamic data (rendering the first time will download chromium locally in a folder named pyppeteer). Commenting out this rendering syntax makes the code equivalent to the BeautifulSoup code. And finally, the names syntax searches for all <span> tags containing both counter-item and counter-item-double as the name of the class (the element <span class="counter-item-double">...</span> corresponds to those counter names that use two lines).
The file world_data.csv looks like this (without rendering, the 2nd column will only show the text retrieving data...):

Next we look at how to scrape Amazon.com with python’s selenium package.

Hi there! I am Roy, founder of Quantiux and author of everything you see here. I am a data scientist, with a deep interest in playing with data of all colors, shapes and sizes. I also enjoy coding anything that catches my fancy.
Leave a comment below if this article interests you, or contact me for any general comment/question.