In the first of this 2-part mini-series on scraping Amazon for data, I described how to write a python code to auto-login to your Amazon.com account. Here I’ll detail another code that automates the process of searching Amazon for a particular item, filtered by its brand name, star rating, and price range. While logging in is not necessary to carry out a search, it can help narrow down the results by user interest and previous search history.
Scraping Amazon for “wet cat food”

The item I’ll be searching for is “wet cat food”, which is something I buy often on Amazon for my cat Toti (seen here meditating). She loves Friskies pâté canned food, so I usually get different combinations of this item. There are three filters in the searching process: the brand name “Friskies”, rating “4 stars & Up”, and maximum price $25.
The way a standard Amazon search goes is as follows. First, I enter the search term “wet cat food” in the search box at the top of the page, and press the search button. Next I choose the filters one-by-one from the left sidebar, and the page reloads after each choice: brand “Friskies” reloads the page with only Friskies brand, rating “4 stars & Up” reloads with only Friskies brand rated 4 stars and above, and lastly, entering \$25 in the max price box and pressing “Go” button reloads the page with only Friskies brand rated 4 stars+ and price ≤$25.
The final outcome of the search process gives me a total of 75 items spread over 4 pages. The python code below is organized to execute these steps in sequence as described. After each page loads, the code scans it and scrapes the name, total price, and price/oz of all items on this page, and moves on to the next page, until the last page is reached. After all pages are scanned, the code saves the data in a file as a pandas data frame.
And as I said before, XPath expression is my preferred selector for such scraping tasks with selenium.
The code
Now the fun begins. First step as usual is to import all needed python modules at the top of the code, which include
#!/usr/bin/env python3
import logging
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWaitselenium modules, along with pandas and logging modules. The logging module is used to log information about intermediate steps of the code, in lieu of a print() statement.
The code snippet below begins defining the main python class AmazonAPI() in terms of its initializer and first method search_amazon(). This method implements all the steps that require entering search parameters, starting with typing “wet cat food” in the search box and clicking it, then narrowing down the results by activating filters one-by-one, by brand name, star rating, and max price. At the end, the first page with search results is loaded.
# main class to run Amazon search
class AmazonAPI:
# initializer
def __init__(self, browser, url, wait) -> None:
self.browser = browser
self.url = url
self.wait = wait
# method to search and load 1st product list page
def search_amazon(self, search_term, brand, rating, max_price) -> None:
# load amazon.com
self.browser.get(self.url)
# send search term to search box
search_box = self.wait.until(
EC.visibility_of_element_located(
(By.XPATH, '//input[@aria-label="Search Amazon"]')
)
)
search_box.send_keys(search_term)
# click search button
search_button = self.wait.until(
EC.visibility_of_element_located(
(By.XPATH, '//input[@id="nav-search-submit-button"]')
)
)
search_button.click()
logging.info("Searching for '%s'...", search_term)
# click brand name
brand_box = self.wait.until(
EC.visibility_of_element_located(
(By.XPATH, '//span[text()="' + brand + '"]')
)
)
brand_box.click()
logging.info("Filtered by brand '%s'", brand)
# click star rating
rating_box = self.wait.until(
EC.visibility_of_element_located(
(By.XPATH, '//section[@aria-label="' + rating + '"]')
)
)
rating_box.click()
logging.info("Filtered by rating '%s'", rating)
# send max price value to high-price box
highprice_box = self.wait.until(
EC.visibility_of_element_located((By.XPATH, '//input[@id="high-price"]'))
)
highprice_box.send_keys(max_price)
logging.info("Filtered by price range '$0-$%s'", max_price)
# click 'Go' button
go_button = self.wait.until(
EC.visibility_of_element_located(
(By.XPATH, '//input[contains(@class,"a-button-input")]')
)
)
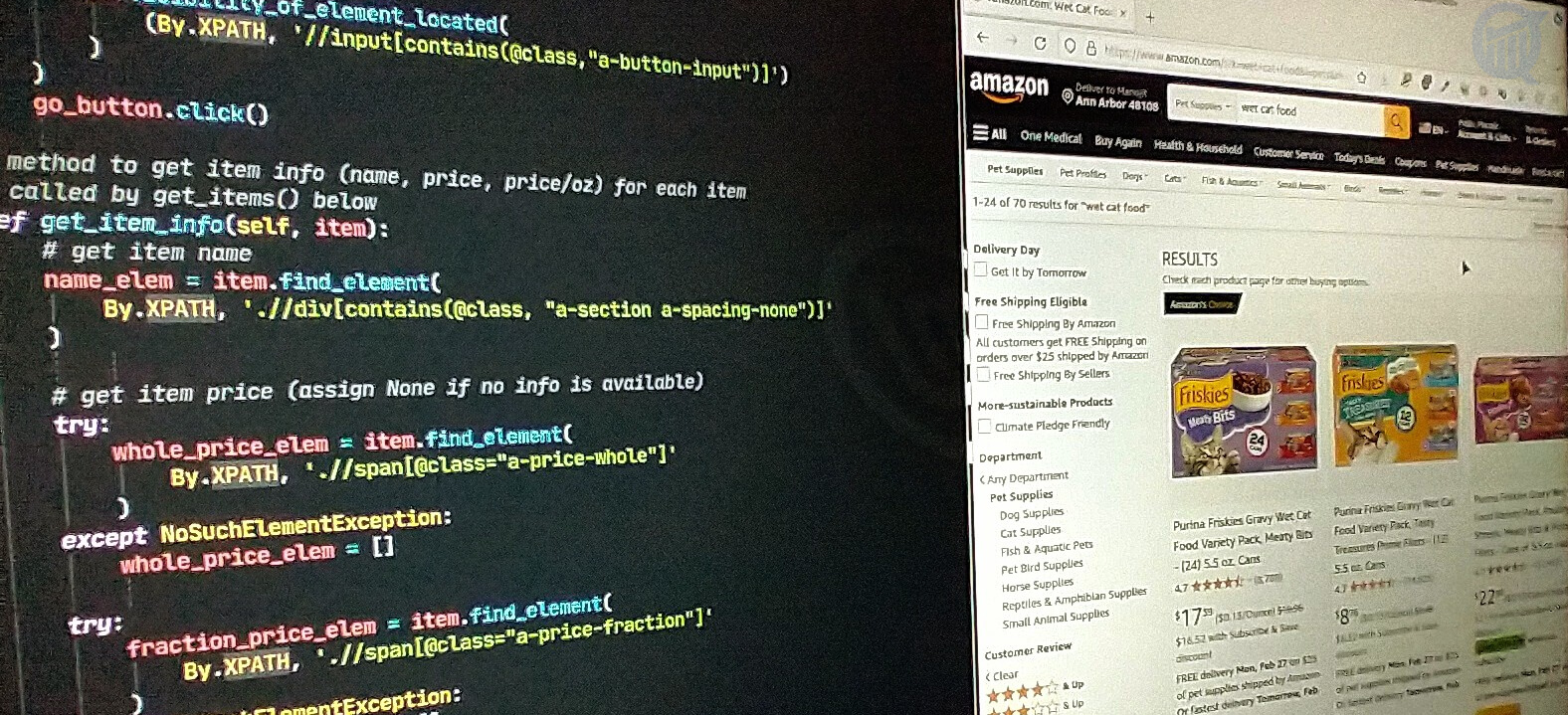
go_button.click() # load 1st page with search resultsOnce the first page (of total 4) of search results loads, real scraping for data begins. Each page consists of the items arranged in a grid pattern, with a short “information card” containing an image of the item, its name, price and price/oz, and other details. The next two code snippets describe two methods, first get_item_info() and then get_items(), which calls the first method get_item_info().

These methods do the following. After the results page loads, get_items() scrapes it for the text portion of the information cards of all items on this page, using the XPath expression //div[contains(@class,"puis-padding-left-small")] (see image on the left) with the selenium method visibility_of_all_elements_located(). It then calls get_item_info() inside a for loop to scrape the item name, price, and price/oz for each item, and continues to the next page inside a while loop until the last page loads.
The code for get_item_info() is shown below. It reads in the item information card (via parameter item) and returns name, price and price/oz. If price or price/oz information is not available, None is returned instead.
# method to get item info (name, price, price/oz) for each item
# called by get_items() below
def get_item_info(self, item):
# get item name
name_elem = item.find_element(
By.XPATH, './/div[contains(@class, "a-section a-spacing-none")]'
)
# get item price (assign None if no info is available)
try:
whole_price_elem = item.find_element(
By.XPATH, './/span[@class="a-price-whole"]'
)
except NoSuchElementException:
whole_price_elem = []
try:
fraction_price_elem = item.find_element(
By.XPATH, './/span[@class="a-price-fraction"]'
)
except NoSuchElementException:
fraction_price_elem = []
if whole_price_elem != [] and fraction_price_elem != []:
price = ".".join([whole_price_elem.text, fraction_price_elem.text])
else:
price = None
# get item price/lb (assign None if no info is available)
try:
rate_elem = item.find_element(
By.XPATH, './/span[@class="a-size-base a-color-secondary"]'
)
rate = rate_elem.text
except NoSuchElementException:
rate = None
# collect item info
item_info = {
"name": name_elem.text,
"price": price,
"price_per_lb": rate,
}
return item_infoNext follows the code for get_items(), which returns a list of name, price and price/oz of all items with brand name “Friskies”, rated 4 stars and above, and price under $25 (a total of 75 items in this example).
# method to cycle through pages and get item name, price and price/lb
def get_items(self):
item_list = []
k = 1
while True: # loop through last page of product list
# get elements for all items on current page
item_elems = self.wait.until(
EC.visibility_of_all_elements_located(
(
By.XPATH,
'//div[contains(@class,"puis-padding-left-small")]',
)
)
)
# extract name, price, price/lb from each item_elem
for item in item_elems:
item_info = self.get_item_info(item) # calls get_item_info()
item_list.append(item_info)
logging.info("Page #%s scanned", k)
# get elements for 'Next' button (to go to next list page) and click it
try:
next_button = self.wait.until(
EC.visibility_of_element_located(
(By.XPATH, '//a[contains(text(),"Next")]')
)
)
except TimeoutException: # last page reached
break # exit while loop
next_button.click()
k += 1
logging.info(
"All pages scanned (%s items found in %s pages)", len(item_list), k
)
return item_listThe data is saved as a pandas data frame in a file, with the following method:
# method to save data
def save_data(self, item_list, file) -> None:
logging.info("Saving data...")
df = pd.DataFrame(item_list)
df.to_csv(file)
logging.info("Done.")We now have the complete definition of the class AmazonAPI(). To wrap it all up, the final step is the main() function that sets up logging configuration, initializes variables including the Firefox browser in headless mode (to speed things up by launching it in the background), creates an AmazonAPI() object, and runs the above-defined methods sequentially to scrape and save the price data in a file. As of this writing, Chrome browser in headless mode has some issues, but works fine without this option.
def main() -> None:
# set logging config
logging.basicConfig(
level=logging.INFO,
format="(%(levelname)s) %(asctime)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
# initialize variables
url = "https://www.amazon.com"
search_term = "wet cat food"
brand = "Friskies"
rating = "4 Stars & Up"
max_price = 25
# initialize Firefox browser (see https://stackoverflow.com/a/56502916)
options = webdriver.FirefoxOptions()
options.add_argument("--headless") # use headless option
browser = webdriver.Firefox(options=options)
browser.set_page_load_timeout(10) # wait-time for page loading to complete
wait = WebDriverWait(browser, 10) # wait-time for XPath element extraction
# run codes
amazon = AmazonAPI(browser, url, wait) # create AmazonAPI() object
amazon.search_amazon(search_term, brand, rating, max_price) # load 1st results page
item_list = amazon.get_items() # get item info for all search results
with open("amazon.csv", "w") as fp: # save data
amazon.save_data(item_list, fp)
# run main function
if __name__ == "__main__":
main()The saved data file amazon.csv should look something like this:


Hi there! I am Roy, founder of Quantiux and author of everything you see here. I am a data scientist, with a deep interest in playing with data of all colors, shapes and sizes. I also enjoy coding anything that catches my fancy.
Leave a comment below if this article interests you, or contact me for any general comment/question.