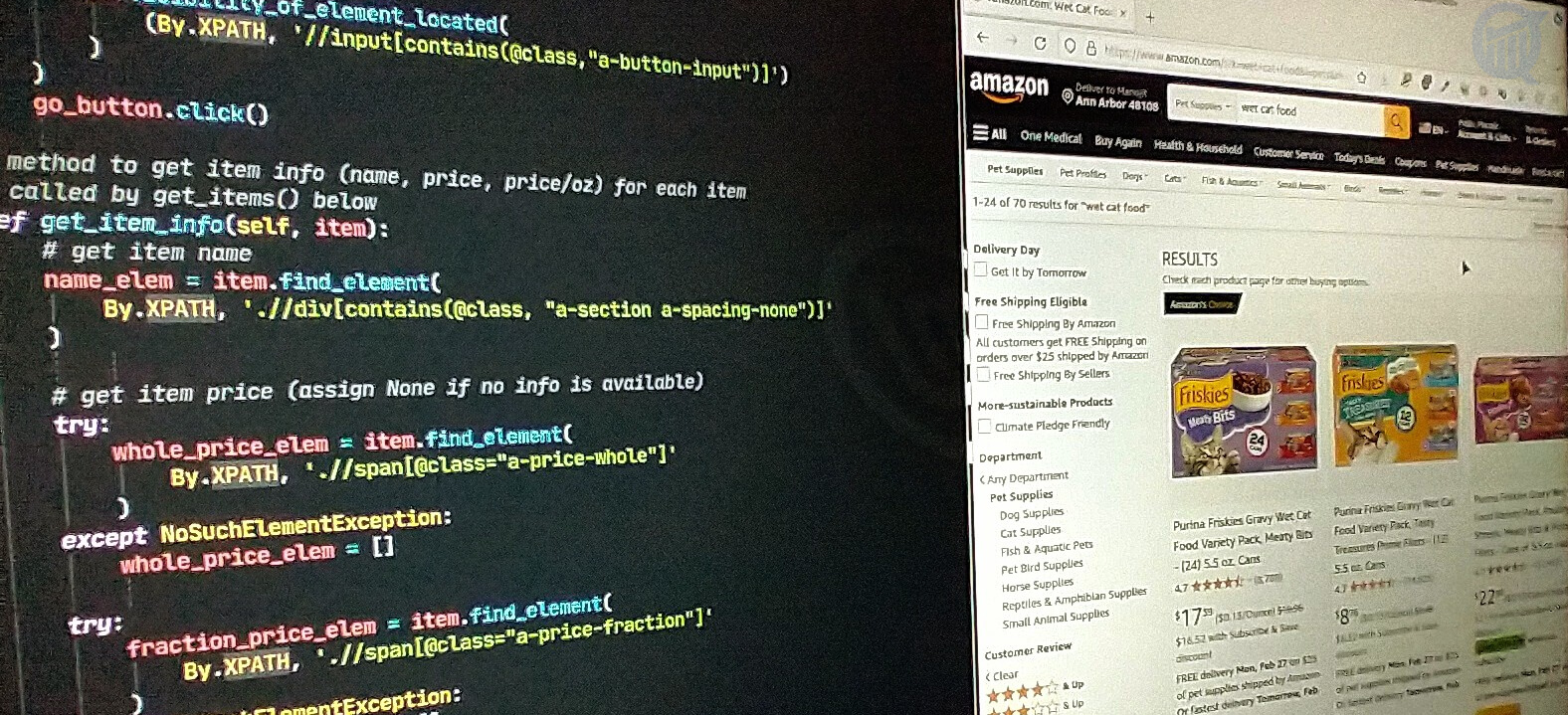
Scraping Amazon with selenium (P.2): Price lookup
In the first of this 2-part mini-series on scraping Amazon for data, I described how to write a python code to auto-login to your Amazon.com account. Here I’ll detail another code that automates the process of searching Amazon for a particular item, filtered by its brand name, star rating, and price range. While logging in […]
Scraping Amazon with selenium (P.2): Price lookup Read More »